-
Antes de iniciar el curso.
0.- Antes de empezar el curso -
Curso profesional de Python1.- Preparación del ambiente de trabajo.
-
2.- Estructura y elementos del lenguaje7 Temas1 Cuestionario
-
3.- Principales métodos del objeto string7 Temas1 Cuestionario
-
4.- Tipos de datos complejos4 Temas1 Cuestionario
-
5.- Funciones definidas por el usuario4 Temas1 Cuestionario
-
6.- Módulos, paquetes y namespaces3 Temas1 Cuestionario
-
7.- POO/OOP (Programación Orientada a Objetos)8 Temas1 Cuestionario
-
8.- Conversión de tipos5 Temas1 Cuestionario
-
9.- Ficheros4 Temas1 Cuestionario
-
10.- Bases de datos con SQLITE33 Temas1 Cuestionario
-
11.- Encuesta sobre el curso
-
12.- Proyecto final2 Temas
Participantes 267




3.1.- Las cadenas y sus principales métodos

Angel Sánchez 21 mayo, 2025
Antes de continuar analizando nuestro código, hablaremos sobre las cadenas. Explicaremos las diferentes codificaciones Unicode, trataremos de entenderlas y luego conoceremos los principales métodos de una cadena en Python.
¿Cuánto sabes de cadenas?
Antes de conocer los diferentes métodos de una cadena en Python, hablaremos un poco sobre ellas. Una cadena es una secuencia de caracteres y cada idioma posee sus propios caracteres; existen idiomas que comparten muchos caracteres entre sí (como el inglés, español, francés, etcétera) y estos a su vez, difieren completamente de otros (como el mandarín, japonés, etcétera).
El inglés posee un total de 26 caracteres -52 si cuentas mayúsculas y minúsculas- más algunos signos de puntuación (!?&$…), mientras que el mandarín por ejemplo, posee miles de caracteres.
Generalmente, cuando piensas en “cadenas” o “texto plano” piensas en una secuencia de caracteres y símbolos guardados en el ordenador, pero los ordenadores no conocen símbolos ni caracteres, conocen bits y bytes. Cada caracter que ves en pantalla está almacenado con una codificación de caracteres específica, que es la que se encarga de convertir lo que está almacenado en el ordenador en lo que ves en pantalla.
Existen diversas codificaciones de caracteres, de las cuales algunas están optimizadas para idiomas como el mandarín o el inglés y otras se utilizan para diferentes idiomas.
Si quieres complicarte un poco más, puedes imaginarte que hay muchos caracteres que son comunes a diferentes codificaciones, pero cada codificación puede utilizar una secuencia diferente para almacenar dichos caracteres. Muchos caracteres son comunes a diferentes codificaciones, pero cada codificación puede utilizar una secuencia de bytes diferente para almacenar esos caracteres en memoria o disco.
Para hacerlo un poco más sencillo, puedes pensar en una codificación en una especie de “clave” para desencriptar información. Cuando poseas una secuencia de bytes (archivo, página web, etc) y dichos bytes representen texto, precisarás conocer la codificación con la que se encuentran almacenados para poder desencriptarlos y obtener así, el caracter que representan. Si posees una clave errónea o simplemente no dispones de una, el desencriptado no será posible o será erróneo, obteniendo así, caracteres erróneos o simplemente texto sin sentido. Un ejemplo claro de esto es cuando ingresas a un sitio web, por ejemplo, y observas caracteres especiales donde esperabas acentos, eñes, etc.
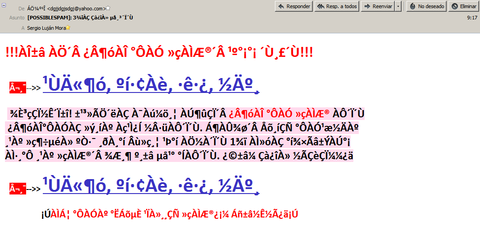
** Esto es un ejemplo de un correo electrónico con una codificación de caracteres errónea.
Tal como dijimos, existen codificaciones de caracteres y cada una de ellas está pensada para uno o varios idioma específicos, dado a que cada idioma es diferente y cada uno de ellos deberá almacenar una cierta cantidad de caracteres diferentes. Por ejemplo, si vienes de otros lenguajes de programación, quizás te suene familiar la codificación ASCII, la cual almacena los caracteres del inglés como números que van del 0 al 127 (65 es la “A”, 97 es la “a”, etc). Dado a que el inglés es un alfabeto muy simple, puede expresarse con menos de 128 números. Si conoces base 2, sabrás que esto significa 7 bits de los 8 de un byte.
Existen otros idiomas que necesitan almacenar más caracteres o poseen combinaciones con diferentes signos diacríticos -como la ñ del español, la diéresis de la ü, etc). La tabla más común para estos idiomas es la CP-1252, que comparte losa primeros 128 caracteres con la codificación ASCII y luego se extiende hasta el 255 para los caracteres restantes (ñ, ü, ó, etc). Lo importante es que continúa siendo una codificación de 1 byte.
Claro está que existen otros idiomas como el mandarín, japonés, etc, que poseen muchas más caracteres y requieren codificaciones de más de un byte, por lo que cada caracter se representa como un número de 2 bytes y pueden almacenar 2^16 caracteres (0 a 65535), pero donde no escapas a que cada una de estas codificaciones pueden utilizar el mismo número para almacenar un caracter diferente.
Ahora, conociendo que existen diversas codificaciones de caracteres, intenta imaginar que se almacenan diversos archivos en una misma base de datos y que cada uno de ellos posee su propia codificación para que puede ser leído correctamente, parece difícil, pero prueba buscando en tu servidor de correos un email puntual; esto implica convertir entre múltiples tablas de codificación de cada mail en cada búsqueda puntual.
Puedes lamentarte un rato, porque puede que todo lo que creías saber sobre cadenas, sea erróneo. Pero no te preocupes, en el próximo video daremos un vistazo a las codificaciones Unicode para entender cómo funcionan.
Conociendo Unicode
Unicode es un sistema de codificación pensado para almacenar todos los caracteres de todos los idiomas, donde cada número de cuatro bytes representa a un único caracter que se use en al menos uno de los diversos lenguajes de mundo. Esto quiere decir que existe un único número por cada caracter y un caracter -independientemente del idioma- será almacenado con el mismo número, por lo cual, el número U+00E1 siempre será el caracter “á”, incluso si el idioma no utiliza dicho caracter.
Esto pareciera ser una muy buena idea, dado a que una misma tabla de codificación nos sirve para cualquier caracter, pero la realidad es que resulta un poco exagerado pensar en 4 bytes para cada caracter en un idioma que puede almacenar todos sus caracteres en un único byte -como el inglés, español, etc-. Es por ello que existen diversas codificaciones Unicode.
La primer codificación es la UTF-32 (de 32 bits correspondientes a 4 bytes). La misma es una codificación directa, donde los caracteres son guardados como números de 4 bytes, pero ya vimos que su gran desventaja es que necesita 4 bytes por cada caracter que se almacene.
La siguiente es UTF-16 (de 16 bits correspondientes a 2 bytes), que almacena cada caracter en un número de 2 bytes. La mayor ventaja es que es el doble de eficiente que UTF-32, dado a que cada caracter requiere únicamente de 2 bytes, pero sigue siendo ineficiente si representamos caracteres del inglés o español.
Existen algunos problemas no tan visibles en UTF-16 y UTF-32, dado a que los ordenadores de diferentes sistemas pueden almacenar los bytes de maneras distintas, esto significa que el caracter U+4E2D puede almacenarse en UTF-16 como 4E 2D o como 2D 4E, dependiendo de la forma en que los números binarios de múltiples bytes son guardados en el sistema (“big-endian” o “little-endian”). Vale aclarar que para UTF-32 existen más combinaciones.
Para esto último, existe la codificación UTF-8 (de 8 bits correspondientes a 1 byte), que es un sistema de codificación Unicode de longitud variable, lo cual implica que los caracteres pueden almacenarse como números de diferentes números de bytes. Para los caracteres ASCII utiliza un único byte y la codificación es igual a la ASCII. Para los demás caracteres especiales -como la ñ, ü, etc- utiliza 2 bytes. Los caracteres del mandarín utilizan 3 bytes y aquellos menos comunes, utilizan 4 bytes.
La principal ventaja de UTF-8 es está muy optimizada para los caracteres ASCII, dado a que solamente utiliza 1 byte para almacenar los mismos y también puede soportar los caracteres de otras codificaciones. Además, en esta codificación no existen problemas de ordenación de bits, por lo que un documento en UTF-8 siempre contiene la misma secuencia de bytes, sin importar el ordenador y sistema operativo.
En Python 3, no debes pensar si una cadena está codificada con UTF-8, ASCII, etc, sino que todas las cadenas son secuencias de caracteres Unicode. Claro está que los caracteres no son bytes, los bytes son bytes, los caracteres son una representación de un número almacenado con una longitud específica de bytes y las cadenas son una secuencia de dichas representaciones.
Si deseas convertir una secuencia de caracteres -llámese cadena- en una secuencia de bytes, puedes hacerlo. Si posees una secuencia de bytes y deseas convertirla en una cadena, también puedes hacerlo.
