Analizar documentos con n8n y OpenRouter (imagen, archivo, audio y video)
En la clase pasada, “Implementación de OpenRouter en n8n”, vimos cómo crear nuestra cuenta de OpenRouter, cómo conectar sus modelos a nuestros agentes y cómo gestionar toda la administración de consumos. Pero nos faltó ver cómo usar OpenRouter con el nodo HTTP Request, para poder acceder a funciones no nativas de n8n, como el procesamiento de imágenes, archivos, audio y video. En este artículo te explico cómo hacerlo.
Modelos para análisis de documentos
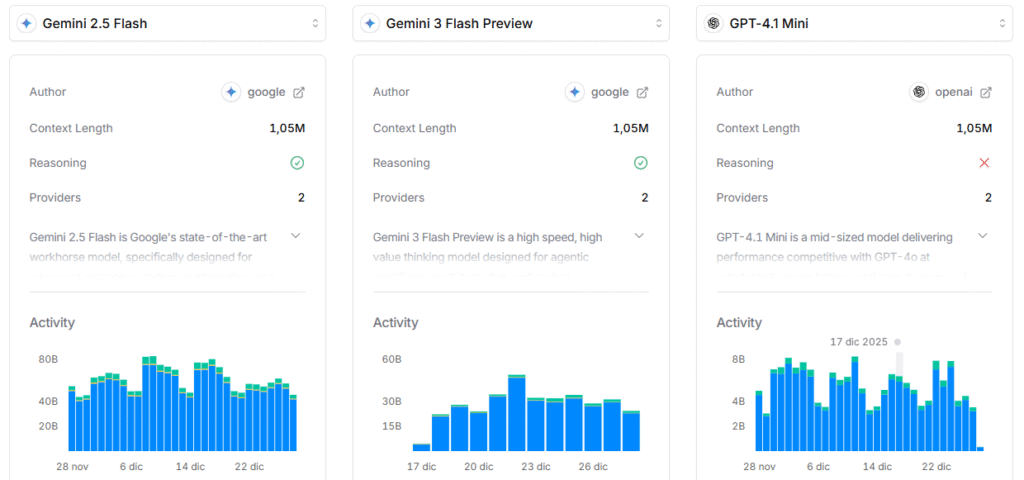
En lo personal, los mejores modelos para analizar documentos, a la fecha de diciembre de 2025, son los que ofrece Google: Gemini 2.5 Flash y Gemini 3 Flash. Ambos modelos pueden procesar hasta 1.05 millones de tokens de contexto y analizar texto, imágenes, archivos y audio. Los precios no varían mucho:
- $0.30 / M tokens vs $0.50 / M tokens de input.
- $2.50 / M tokens vs $3.00 / M tokens de output.
¿Cuándo usar cada modelo?
Para el uso diario y tareas simples, recomiendo Gemini 2.5 Flash. Para tareas más complejas, recomiendo Gemini 3 Flash. Ambos tienen modo de razonamiento, pero he obtenido mejores resultados con Gemini 3 Flash.
Por ejemplo, tenemos un cliente donde debemos analizar un recibo de CFE, pero no hay un patrón fácil de identificar, por lo cual modelos como el 2.5 no me han ayudado. En cambio, con Gemini 3 Flash en modo razonamiento he logrado el resultado deseado.
Cómo implementarlo en n8n
Lo primero que vamos a hacer es entender cómo realizar la solicitud. En OpenRouter hay ejemplos, o bien puedes pedirle a una IA que te ayude a armar el curl. Aquí te dejo uno de ejemplo para una imagen con Gemini 3 Flash:
curl https://openrouter.ai/api/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-d '{
"model": "google/gemini-3-flash-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "¿Qué objetos ves en esta imagen?"
},
{
"type": "image_url",
"image_url": {
"url": "https://ejemplo.com/imagen.jpg"
}
}
]
}
],
"reasoning": {
"effort": "high"
}
}'
En lo que debes poner atención es en lo siguiente:
$OPENROUTER_API_KEY: debes quitar esto y poner tu API Key. Ya vimos cómo hacerlo en Implementación de OpenRouter en n8n.google/gemini-3-flash-preview: este es el modelo que vas a usar; en este caso, Gemini 3 Flash.- “¿Qué objetos ves en esta imagen?”: este es el prompt; aquí vas a colocar lo que deseas obtener de la imagen.
"url": "https://ejemplo.com/imagen.jpg": aquí vas a colocar la URL de la imagen."effort": "high": es para el modo de razonamiento. Tiene estas opciones:- “low”: razonamiento mínimo, respuestas rápidas (1,024 tokens de pensamiento).
- “medium”: balance entre velocidad y profundidad (8,192 tokens).
- “high”: máximo razonamiento para tareas complejas (24,576 tokens).
- “none”: solo para modelos Gemini 2.5 (Gemini 3 no puede desactivarse completamente).
Una vez que tengas ese curl, lo copias y abres un nodo en n8n de HTTP Request. Das clic para ver sus configuraciones y, en la parte superior derecha, haces clic donde dice “Import cURL” y pegas el comando.
Plantilla n8n
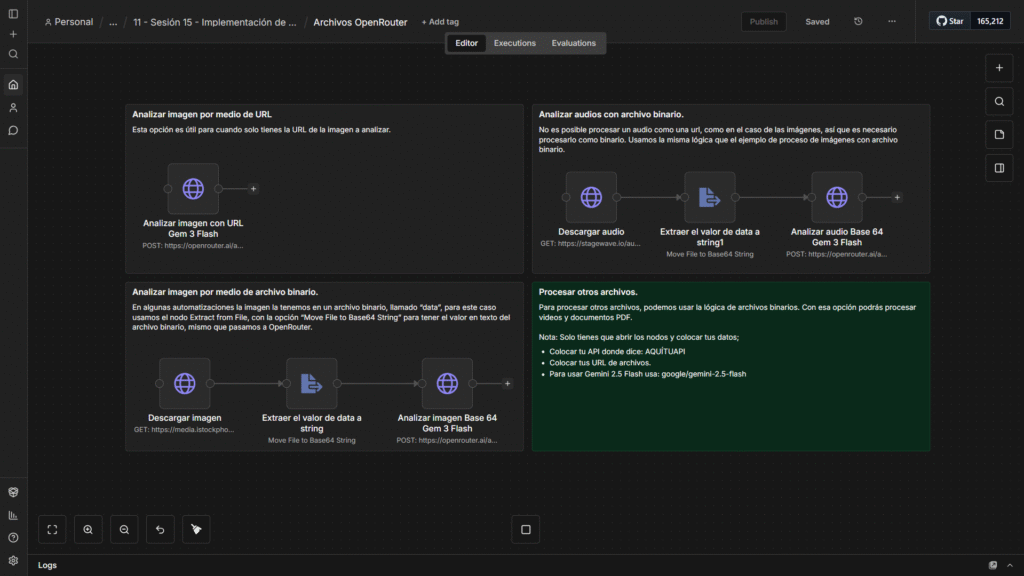
Te dejo una plantilla de n8n con ejemplos para procesar imágenes y documentos, con dos métodos: URL y archivo binario. Solo tienes que importarla y colocar tus datos.
Link: Descargar plantilla.
¿Quieres aprender a trabajar con n8n desde cero?
En Azul School puedes aprender todo lo necesario para crear automatizaciones y agentes de IA con n8n, sin experiencia previa. Nuestra plataforma incluye clases en vivo, cursos profesionales paso a paso, y acompañamiento personalizado para ayudarte a lanzar tus propios proyectos.
- Haz clic aquí para adquirir tu membresía y comenzar ahora mismo.
- ¿Prefieres que te expliquemos todo en una reunión? Haz clic aquí para hablar con Grecia, nuestra agente de IA, y agenda una llamada para conocer toda nuestra oferta educativa.
¡Te esperamos en Azul School!




Respuestas